Python環境が使えるDockerを準備する
目的
Pythonで業務上のツールを作成する際にサクッと用意できる環境を準備するのに毎回時間がかかっているため、簡潔にやることだけをまとめた資料を用意したい
今回は運用保守対応時によくある集計ツールを作成することを目的に環境構築をしていきます
前提
私はMac OS 15.5を使っています
手順
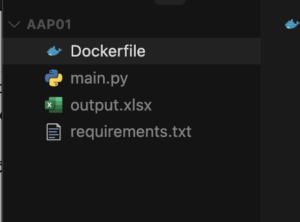
ファイル構成はこんな感じです
Dockerfile
FROM python:3.12-slim
# システムアップデート & 必要なパッケージのインストール
RUN apt-get update && apt-get install -y \
gcc \
build-essential \
libpq-dev \
libxml2-dev \
libxslt1-dev \
default-libmysqlclient-dev \
&& rm -rf /var/lib/apt/lists/*
# 作業ディレクトリ
WORKDIR /app
# 依存関係コピー・インストール
COPY requirements.txt .
RUN pip install --upgrade pip
RUN pip install -r requirements.txt
# スクリプトコピー
COPY . .
# エントリポイント(任意)
CMD ["python", "main.py"]requirements.txt(ライブラリの管理)
pandas
openpyxl
mysql-connector-pythonmain.py
import pandas as pd
import mysql.connector
from openpyxl import load_workbook
# Aurora MySQL 接続設定
db_config = {
'host': 'your-cluster.cluster-xxxxxxxxxxxx.ap-northeast-1.rds.amazonaws.com',
'user': 'your_user',
'password': 'your_password',
'database': 'your_database',
'port': 3306
}
# 実行するSQL
query = "SELECT * FROM your_table LIMIT 100;"
# Excel出力設定
excel_path = "output.xlsx"
sheet_name = "Sheet1"
start_row = 5
start_col = 1
# データ取得
conn = mysql.connector.connect(**db_config)
df = pd.read_sql(query, conn)
conn.close()
# Excelに出力
wb = load_workbook(excel_path)
ws = wb[sheet_name]
for i, row in df.iterrows():
for j, value in enumerate(row):
ws.cell(row=start_row + i, column=start_col + j, value=value)
wb.save(excel_path)
今回はAWSのRDSへ接続して集計するための土台作りをしました。
Docke環境を構築できるかテストします。
docker build -t mysql-excel-tool .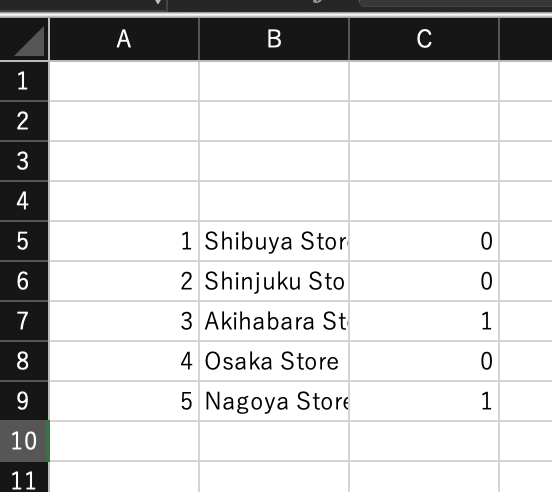
しっかりExcel出力設定の通りに出力できました。
